
LLM Ölçeğinin Yükselişi (ve Riski)
By
Levent Kocatürk
Tarih 30 Mayıs 2025
Son birkaç yılda Büyük Dil Modellerinin (LLM’lerin) boyutunda ve performansında yaşanan devasa sıçramaya hepimiz tanık olduk:
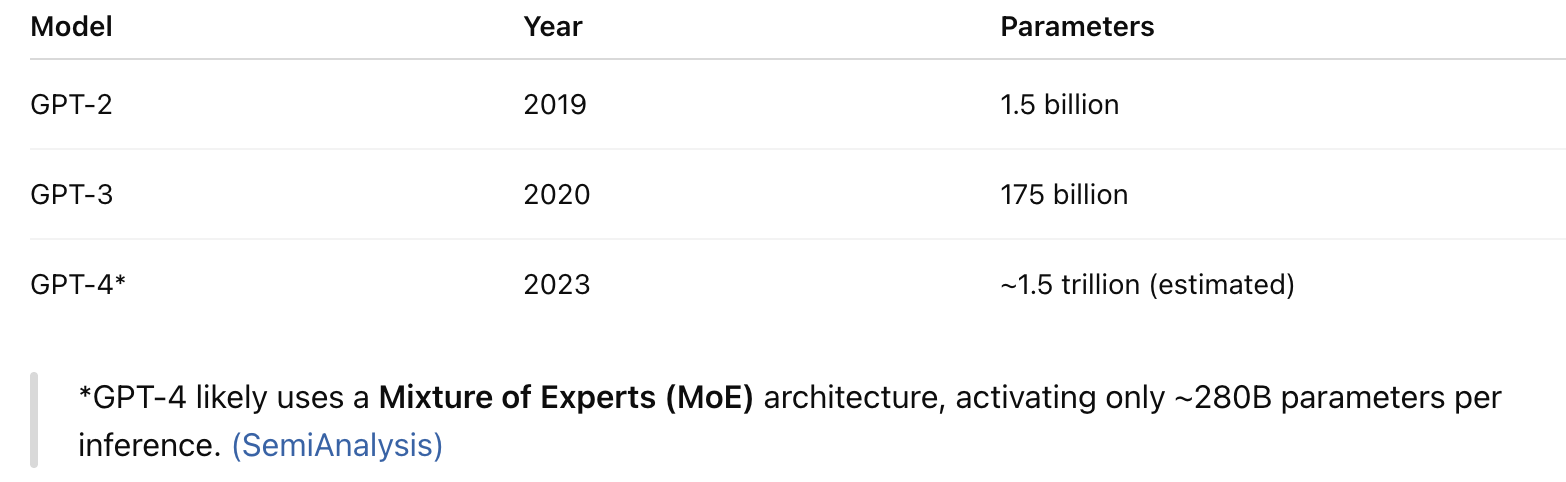
Doğal olarak herkesin aklındaki soru şu: GPT-5 ne kadar büyük olacak? 2 trilyon parametre mi? 10 trilyon mu? Daha da fazlası mı?
Ama işte burada işler karmaşıklaşmaya başlıyor.
Taklit Tuzağı
ChatGPT, Claude ve Bard gibi araçlar yaygınlaştıkça, çevrimiçi içeriklerin—makalelerin, kodların, hatta videoların—büyük bir kısmı ya yapay zeka tarafından üretiliyor ya da ondan etkileniyor.
Bu da bir geri besleme döngüsü yaratıyor. Gelecekteki LLM’ler, önceki LLM’lerin dijital çıktılarıyla eğitiliyor olacak.
Bu, araştırmacıların “model çöküşü” (model collapse) dediği duruma yol açıyor—modeller, çeşitli ve özgün insan içeriği yerine birbirlerinden öğrenmeye başlıyor. (Shumailov et al., 2023)
Riskler mi?
- Tekrarlayan öğrenme
- Yenilik kaybı
- Yetkinliklerin tıkanması
👤 Benim Bakış Açım
Yapay zeka destekli sistemleri yakından takip eden (ve onlarla çalışan) biri olarak, artık sadece ölçek büyütmenin çözüm olmadığını hissetmeye başladım.
Artık öyle bir aşamaya geldik ki, veri kalitesi, kaynağın özgünlüğü ve eğitim stratejisi, sadece parametre sayısından çok daha önemli hale geliyor.
Şu soruyu da sormak gerek:
Modelleri insan bilgisini anlamaları için mi eğitiyoruz, yoksa sadece makinelerin yazdıklarını remixlemeleri için mi?
Bu sorun, gelecek nesil LLM’leri şekillendirecek.
Ne Yardımcı Olabilir?
- Eğitim verilerinin daha iyi kürasyonu
- İçeriklerin insan mı, yapay zeka mı olduğu bilgisinin izlenmesi
- Geri-getirim (retrieval-based) ya da hibrit mimarilerin benimsenmesi
- “Büyük olan iyidir” anlayışını sorgulamak
Son Düşünce
LLM’lerin geleceği sadece parametre sayısına sıfır eklemekle ilgili değil—modelleri ayakta tutan, çeşitli kılan ve gerçek dünya mantığıyla hizalayan bir eğitim sürecini evrimleştirmekle ilgili.
Yapay zeka, makine öğrenmesi ve veri topluluklarındaki diğer kişilerin bu konuyu nasıl ele aldığını merak ediyorum.
Gerçekten bir ölçek tavanına mı ulaşıyoruz—yoksa yepyeni bir zorluğun kapısını mı aralıyoruz?